去年の秋に『自分の日本語』という本を出版し、付属の日本語データベースも仮完成したので、今は、このデータを基にAIのいろいろをやっています。
購入者用ページ(要パス)では、AI活用のいろいろとシェアしています。教師向けコーナーでは以下みたいなかんじです。データを基に大量に作業をさせる際のプロンプトなどが中心です。
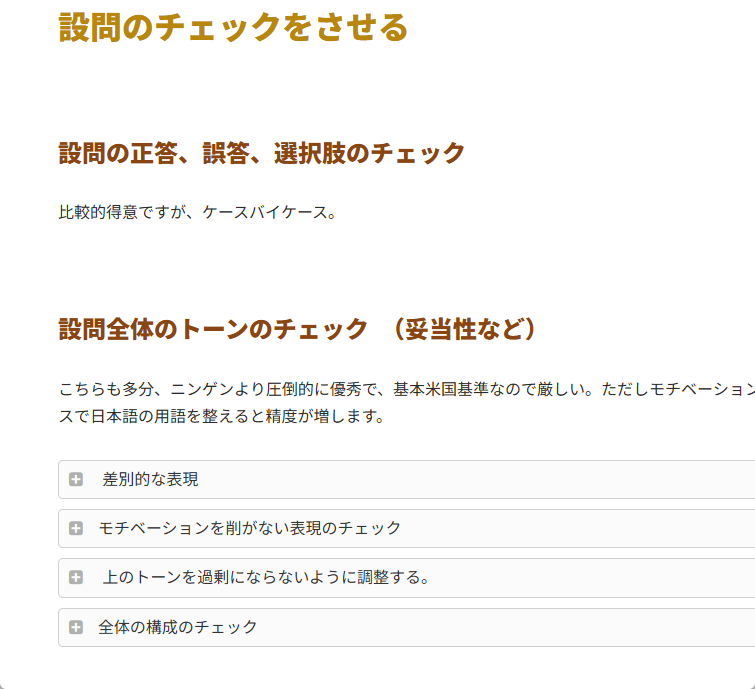
その一部を時々、SNSなどに投稿しています。体系立ててやってることではなく、似たようなことをしてる人がいたら「そうやってる人もいるのか」と伝わるかな、ぐらいのかんじでやっているので、多分、何をしているのか分からない人も多いと思いますが、それは考慮せずに、いろいろ考えながらやってる人には刺さるで十分というという考え方でやってます。
日本語教育の世界は離職率が高いこともあるせいか、初心者、新人向けコンテンツは多いけど中級者、その上向けのコンテンツは極端に少ない傾向があります。今後は中級より上の人達のためにいろいろとやっていく所存です。基本、デジタルの基本知識があり、コンテンツ制作に意欲がある。AIの活用もする、英語も必要なら読む、日本語教育の勉強は論文1を読むことを軸にやっている、という人がターゲットです。Google スプレッドシートなど大量データを扱って何かを作るというのが主なテーマです。
それはともかく、自分の日本語関連のものは、そこそこ大きなプロジェクトなので、SNSに投稿するのはほんの一部です。外部で公開するのは細部のツメや全体の構成案などが中心になります。
notebookLMの活用
geminiを介してのGoogle スプレッドシートなどのツールとnotebookLMとの連携も可能になりました。特に音声や動画生成、サマリーなどはツールとして使えるかもしれません。
notebookLMにいろいろ機能が追加されていることはチェックするだけだったので、久しぶりに実際にやってみました。前に何かやったのは英語の音声解説だったので、その後のもろもろは始めてです。
素材は、『自分の日本語』関連コンテンツで使う予定の誤用傾向のデータです。notebookLMに寺村のデータベースと、その他論文を放り込んでいましたので、それを元に生成させてみました。追加した論文は多数ありますが、素材としてマークしたのは5つほど。テストなので。
結果
画像化
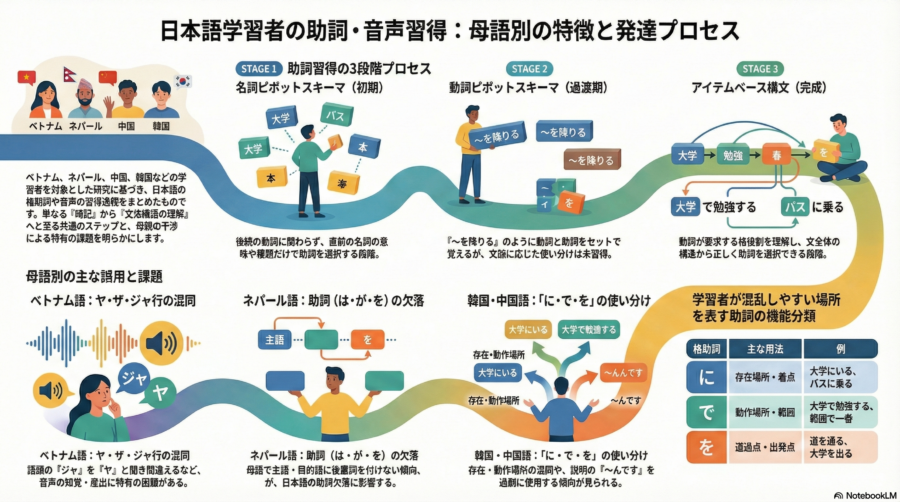
プレゼン用ファイル的なもの
The_Cognitive_Science_of_Error
自動生成されたレポート
日本語学習者における格助詞および文法要素の習得過程と誤用分析:ブリーフィング文書
音声ファイル
ところどころつまんで、それっぽいこと感想を言い合うみたいなノリは変わらず。使いどころがわからないですが、音声ブックみたいなファスト的なニーズがあるので仕方ないのか。
結局、テキスト系でも生成したものを再編集しないとダメなので、そのへんの知識やスキルが無い人は利用できないわけですが、いろいろとソースを絞り込んだり、プロンプトで調整すればよくなる予感はあります。ただ、手間は大変そう。というかんじでした。
ちなみに以下は「外国人学習者の日本語誤用例集」に絞って作らせたレポートです。
誤用はAI活用で結構重要
誤用分析は多分、AIでやるよりも、ビッグデータでやれば済むことという気がします。ただ、ちゃんと許諾をとってやってるところは無いので、今のところ個別の研究を総合して一定の傾向を集めていくしかなさそうです。
誤用の傾向は、AI生成に加味する情報としても価値があります。母語によって生成する説明やドリルの生成にも影響を加味できますし、もろもろを加味した母語別の説明の濃淡など最適化の方向がひとつあります。母語の影響2は日本語教育でもいろいろ研究がありますが、直説法が主流ということもあるのか、いまひとつ生かし切れていないところがあります。
NotebookLMに関する感想
チャットであれこれと概要について尋ねると、そこそこ応えてくれるが、ボンヤリ感は変わらず。ただ情報の抽出はちょっとよくなった?
誤用分析については、書いてることの整理はしても、誤用そのものの理解が怪しく、やはりあいからずAIにとっての、文に関して、間違うということの価値の低さを感じる。抽出した誤用の傾向をふまえて誤った文を作らせると、初期(23年)よりもちゃんと対応するが、指示文を作るのは工夫が必要。
論文からの要旨の抽出は、抽出まではやっても、それをふまえて何かをやるのは苦手っぽい。間違った文を作るのが苦手なのはAIの文生成の手法からして永遠に苦手なのかも?
寺村リストからの抽出は、もうちょっと元データの記述ルールを補足すれば精度は上がりそう。つまり、誤用の蓄積と蓄積の方法(明確な定義とタグ付け)によっては、よいものになりそうな予感もします。
誤用の分析は、やってくれるならAIが役に立ちそうですが、もうひとつ、意図的に間違った文を作るのは、設問などの選択肢を作るのが思いつきますが、例えば、教師養成などでも使えそうです、意外と使える。しかし、どうやらAIが日本語の文を作る方法そのものと相性が悪いようで、初期からいろいろやってますが、うまく間違ってくれません。AIには文が間違っているとか正しいという概念が無いかもしれませんし、それは、文というのものの理解として間違っているとも言えないような気もします。いろいろ議論があるところで、つまり、文が間違っているとは何か?みたいなことです。あるいは、歩き方を教えて、ずっと歩いて生活させておいて、急に後ろ向きに歩けと言ってるようなこと?
👉 国立国語研究所学術情報リポジトリ https://repository.ninjal.ac.jp/records/3550
👉 ちなみに、寺村の誤用データベースは、PDFとテキストで配布されています。テキスト版をDLし、ChatGPTでデータ部分だけスプレッドシートに変換した後、notebookLMに放り込むという手順です。この種の加工、知ってる人は何も考えずにできますが、知らない人はそのままPDFで放り込む人もいるかもしれないので補足。PDF→エクセル変換よりも圧倒的にちゃんとできます。この種のデータ的なものはPDFのままと、スプレッドシートに加工するのとで全然違います。